FlowSeek: Optical Flow Made Easier with Depth Foundation Models and Motion Bases
ICCV 2025
|
|
|
|
|
{kind=link}

|
|
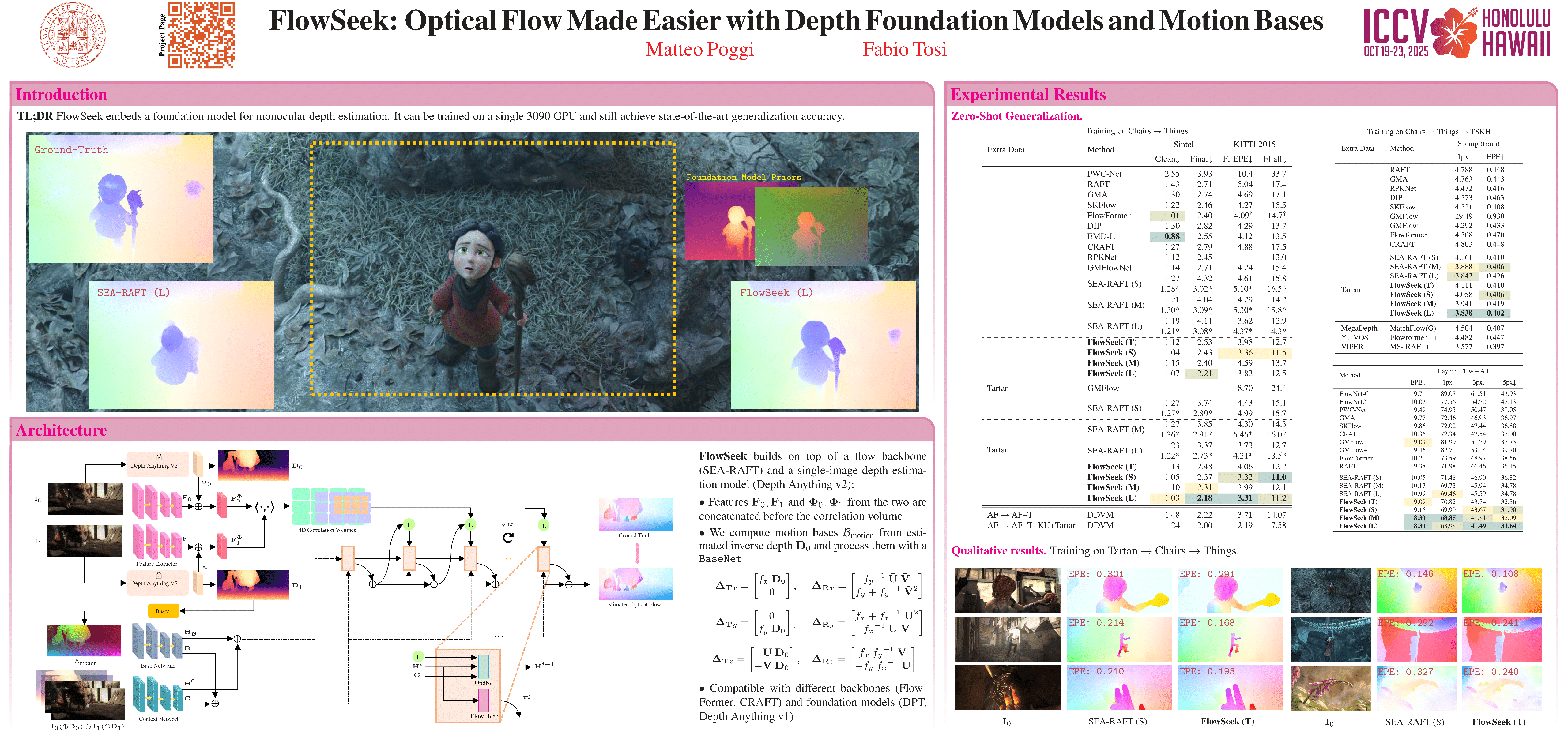
FlowSeek in Action. State-of-the-art optical flow models struggle at generalizing across different domains, with a lack of fine details in their predictions. FlowSeek achieves superior generalization by exploiting the strong priors from depth foundation models. |
Abstract
|
We present FlowSeek, a novel framework for optical flow requiring minimal hardware resources for training. FlowSeek marries the latest advances on the design space of optical flow networks with cutting-edge single-image depth foundation models and classical low-dimensional motion parametrization, implementing a compact, yet accurate architecture. FlowSeek is trained on a single consumer-grade GPU, a hardware budget about 8× lower compared to most recent methods, and still achieves superior cross-dataset generalization on Sintel Final and KITTI, with a relative improvement of 10 and 15% over the previous state-of-the-art SEA-RAFT, as well as on Spring and LayeredFlow datasets. |
Method
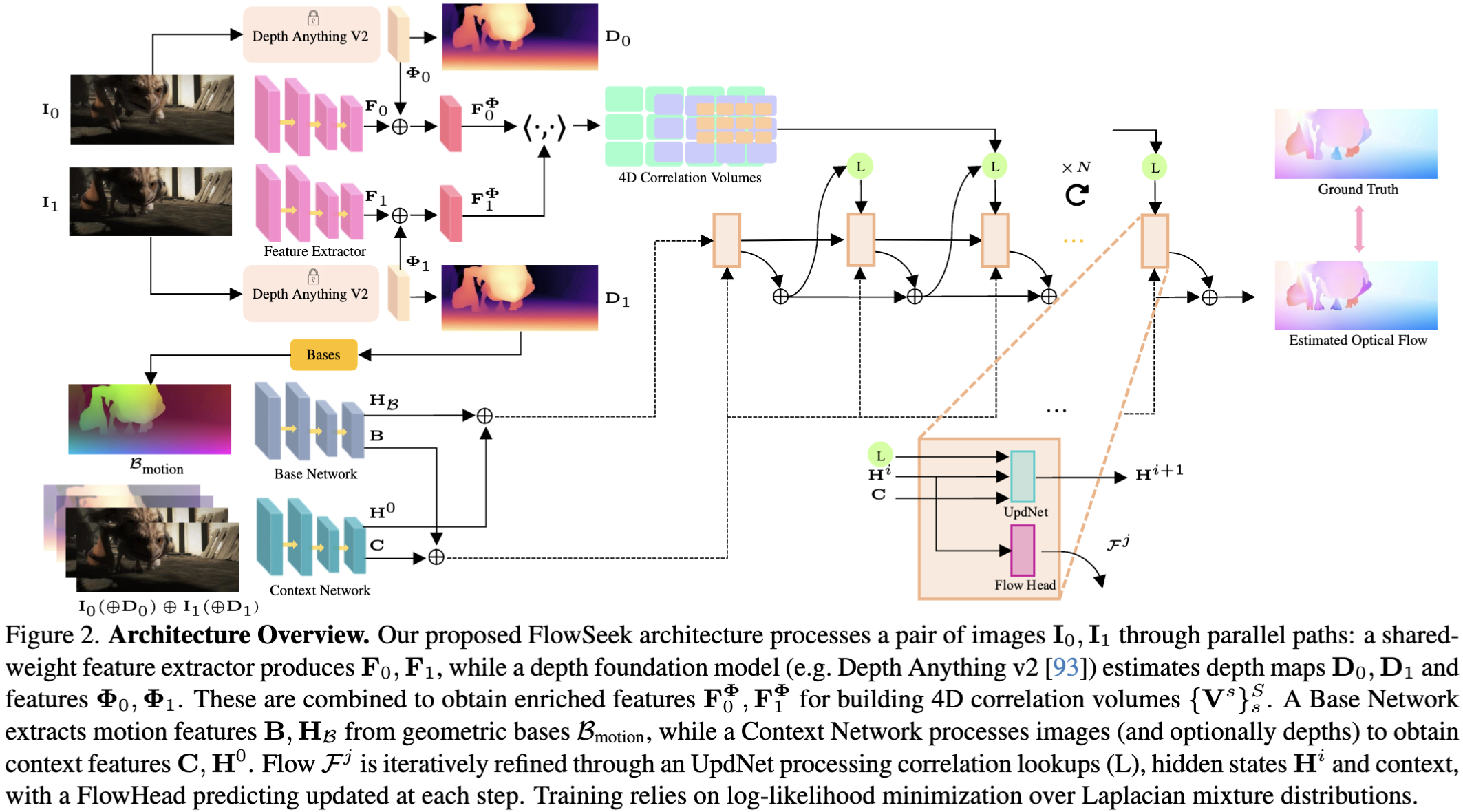 |
Qualitative results
Sintel
 |
KITTI 2015
 |
Spring
 |
BibTeX
@InProceedings{Poggi_2025_ICCV,
author = {Poggi, Matteo and Tosi, Fabio},
title = {FlowSeek: Optical Flow Made Easier with Depth Foundation Models and Motion Bases},
booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)},
year = {2025},
}